VS Code ekibi, GitHub Copilot’un token kullanımını ciddi şekilde azaltan bir dizi optimizasyon yayınladı. 17 Haziran 2026 tarihli blog yazısında dört temel teknik anlatılıyor: extended prompt caching, tool search, WebSocket bağlantıları ve smarter prompt caching. Sonuçlar somut: bazı senaryolarda token kullanımı yüzde 10’a yakın düşmüş, cache hit oranları yüzde 919’a varan artışlar göstermiş.
1. Extended prompt caching (OpenAI)
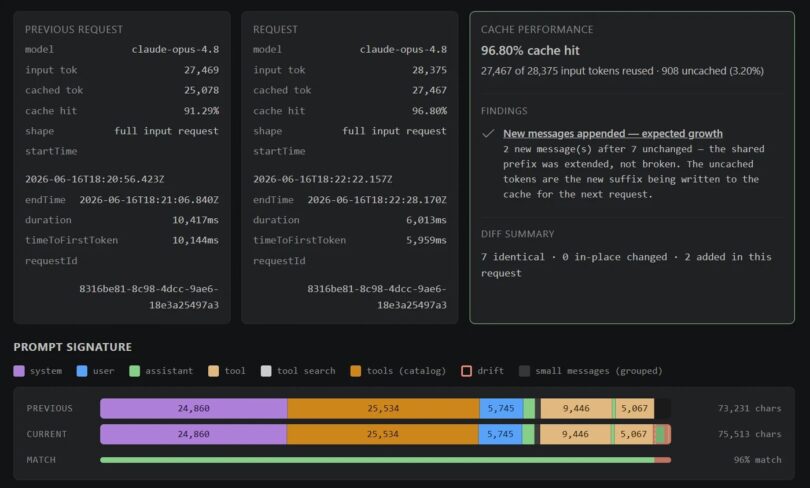
Ekip OpenAI tarafında prompt_cache_retention: "24h" ayarını etkinleştirdi. Bu ayar, cache’lenmiş model state’ini hızlı GPU memory’sinden daha yavaş GPU-local storage’a taşıyor. Bunun pratik sonucu: cache yaşam süresi 5-10 dakikadan 24 saate çıkıyor. Yani uzun bir ara verseniz bile cache’lenmiş inference state korunuyor.
GPT-5.4 için yapılan ölçümlerde, 40-60 dakikalık aralardan sonra cache hit oranı yüzde 919 artmış. Yani geliştirici öğle yemeğine çıkıp dönse bile, döndüğünde Copilot eski cache’ten faydalanabiliyor.
2. Tool search (on-demand loading)
Önceden her request’te tüm tool tanımları model’e yükleniyordu. Şimdi model önce hafif metadata görüyor; tam parametre şeması ancak model belirli bir tool’u aradığında yükleniyor.
Anthropic tarafında bu daha da geliştirilmiş: server-side search’ten client-side search’e geçilmiş. Client tarafında embedding-guided matching ile tool aranıyor.
Sonuçlar oldukça etkileyici:
- GPT-5.4: %8.97 token azalması
- GPT-5.5: %10.92 token azalması
- Anthropic server-side: %18.32 prompt-token azalması (p50, kullanıcı başına)
- Anthropic client-side: %1.91 TTFT iyileşmesi, %4.01 user error azalması (Claude Sonnet 4.6)
3. WebSocket bağlantıları (OpenAI)
Sıralı HTTP request’lerin yerini OpenAI’ın Responses API WebSocket modu üzerinden kalıcı WebSocket bağlantıları aldı. Bu, son response state’lerinin connection-local in-memory cache’lenmesini sağlıyor.
GPT-5.3-Codex’te p50 TTFT (Time To First Token) %19.46 iyileşmiş. GPT-5.4’te aktif kullanıcı sayısı %2.17 artmış. Yani sadece hız değil, kullanıcı memnuniyeti de yansıyor.
4. Smarter prompt caching (Anthropic)
Anthropic için dört kasıtlı cache_control kontrol noktası yerleştirilmiş, hepsi stabil sınırlarda: tool tanımlarından sonra, system prompt’tan sonra ve iki rolling message anchor’da.
Bu yapılandırma, agentic iş yüklerinde %94 cache hit oranını koruyor. Yani agent uzun bir sohbet yürütürken bile çoğunlukla cache’ten faydalanıyor.
Core tool stratejisi
Önemli bir detay: core tool’lar (dosya okuma/düzenleme, terminal komutları, workspace search) hep yüklü kalıyor. Diğerleri ertelenebiliyor. Bu yaklaşım cache invalidation’ı önlüyor ve turn’ler arasında prefix’in yeniden kullanılabilirliğini koruyor.
Desteklenen modeller
- OpenAI: GPT-5.2, GPT-5.3-Codex, GPT-5.4, GPT-5.5
- Anthropic: Claude Opus 4.6, Claude Sonnet 4.6
Sırada ne var?
VS Code ekibinin önümüzdeki dönemde planladıkları arasında iki başlık öne çıkıyor:
Bu optimizasyonlar AI coding asistanlarının ekonomisini anlamak açısından oldukça öğretici. Cache’leme, tool yüklemenin gecikilebilir olması ve persistent connection’lar gibi web ölçeğinde bilinen tekniklerin LLM dünyasına uygulanması, hem maliyeti hem de kullanıcı deneyimini iyileştiriyor. Özellikle “Copilot bana ne kadara mal oluyor?” sorusunun cevabını arayan ekipler için ürün arayüzünde gelecek şeffaflık güzel bir gelişme olacak.
Kaynak: https://code.visualstudio.com/blogs/2026/06/17/improving-token-efficiency-in-github-copilot