Google Research, ICLR 2026’da sunulacak TurboQuant adlı yeni bir sıkıştırma algoritmasını tanıttı. AI modellerinin bellek darboğazlarını çözmek için tasarlanan bu yaklaşım, vektörleri aşırı derecede sıkıştırırken doğruluk kaybını sıfıra yakın tutuyor. Kulağa “her şeyin hem küçük hem güzel olabileceği” iddiası gibi gelebilir ama testler bunu destekliyor.
Vector quantization neden önemli?
AI modelleri bilgiyi vektörler aracılığıyla anlıyor ve işliyor. Basit vektörler bir grafikteki noktayı tanımlarken, yüksek boyutlu vektörler bir kelimenin anlamı, bir görüntünün özellikleri veya bir veri setinin tamamı gibi karmaşık bilgileri taşıyabiliyor. Sorun şu ki bu yüksek boyutlu vektörler çok fazla bellek tüketiyor. Özellikle key-value cache denen, sık kullanılan bilgileri hızlı erişim için saklayan yapıda ciddi darboğazlar oluşuyor.
Vector quantization, bu soruna klasik bir çözüm. Yüksek boyutlu vektörlerin boyutunu küçülterek hem vector search (büyük ölçekli AI ve arama motorlarını besleyen yüksek hızlı benzerlik arama teknolojisi) işlemlerini hızlandırıyor hem de key-value cache tıkanıklığını azaltıyor. Ama geleneksel yöntemlerin bir sıkıntısı var: çoğu yöntem, her küçük veri bloğu için tam hassasiyette quantization sabitleri hesaplayıp saklamak zorunda kalıyor. Bu ek bellek yükü, eleman başına 1-2 ekstra bit ekliyor ve sıkıştırmanın amacını kısmen boşa çıkarıyor.
TurboQuant nasıl çalışıyor?
TurboQuant, bu bellek yükü sorununu iki aşamalı bir yaklaşımla çözüyor.
Birinci aşamada PolarQuant devreye giriyor. TurboQuant, veri vektörlerini rastgele döndürerek başlıyor. Bu adım verinin geometrisini sadeleştiriyor ve standart bir quantizer’ın (sürekli değerleri, tam sayılar gibi daha küçük, ayrık bir kümeye eşleyen araç) her parçaya ayrı ayrı uygulanmasını kolaylaştırıyor. Bu aşama sıkıştırma gücünün büyük bölümünü kullanarak orijinal vektörün ana kavramını ve gücünü yakalıyor.
İkinci aşamada QJL algoritması giriyor. Birinci aşamadan kalan küçük hata miktarına sadece 1 bit sıkıştırma gücü uygulayarak matematiksel bir hata kontrolcüsü gibi çalışıyor ve bias’ı ortadan kaldırıyor. Sonuç olarak daha doğru attention score’lar elde ediliyor.
QJL: Sıfır ek bellek yüküyle 1-bit sıkıştırma
QJL, Johnson-Lindenstrauss Transform adlı matematiksel bir teknik kullanıyor. Bu teknik, yüksek boyutlu veriyi, veri noktaları arasındaki mesafeleri ve ilişkileri koruyarak küçültüyor. Her sonuç vektörünü tek bir sign bit’e (+1 veya -1) indiriyor. Yani sıfır bellek yükü ile çalışan bir yüksek hızlı kısayol oluşturuyor.
Doğruluğu korumak için QJL, yüksek hassasiyetli query ile düşük hassasiyetli sıkıştırılmış veriyi stratejik olarak dengeleyen özel bir estimator kullanıyor. Böylece modelin hangi girdilerin önemli olduğuna karar verme süreci olan attention score hesaplaması doğru kalıyor.
PolarQuant: Sıkıştırmaya farklı bir açı
PolarQuant, bellek yükü sorununu tamamen farklı bir yoldan çözüyor. Standart koordinatlar (X, Y, Z) yerine vektörü polar koordinatlara dönüştürüyor. Bunu şöyle düşünebilirsiniz: “3 blok doğuya, 4 blok kuzeye git” yerine “5 blok toplam, 37 derece açıyla git” demek gibi. Sonuçta iki bilgi parçası kalıyor: verinin ne kadar güçlü olduğunu gösteren radius ve verinin yönünü/anlamını gösteren açı.
İşin güzel tarafı şu: açıların dağılımı bilinen ve oldukça yoğunlaşmış bir yapıda olduğu için, model artık pahalı data normalization adımını yapmak zorunda kalmıyor. Sınırların sürekli değiştiği “kare” bir grid yerine, sınırları önceden bilinen sabit bir “dairesel” grid üzerinde çalışıyor. Geleneksel yöntemlerin taşımak zorunda olduğu bellek yükünü bu sayede ortadan kaldırıyor.
Test sonuçları
Üç algoritma da LongBench, Needle In A Haystack, ZeroSCROLLS, RULER ve L-Eval dahil standart long-context benchmark’ları üzerinde Gemma ve Mistral gibi açık kaynak LLM’lerle test edildi.
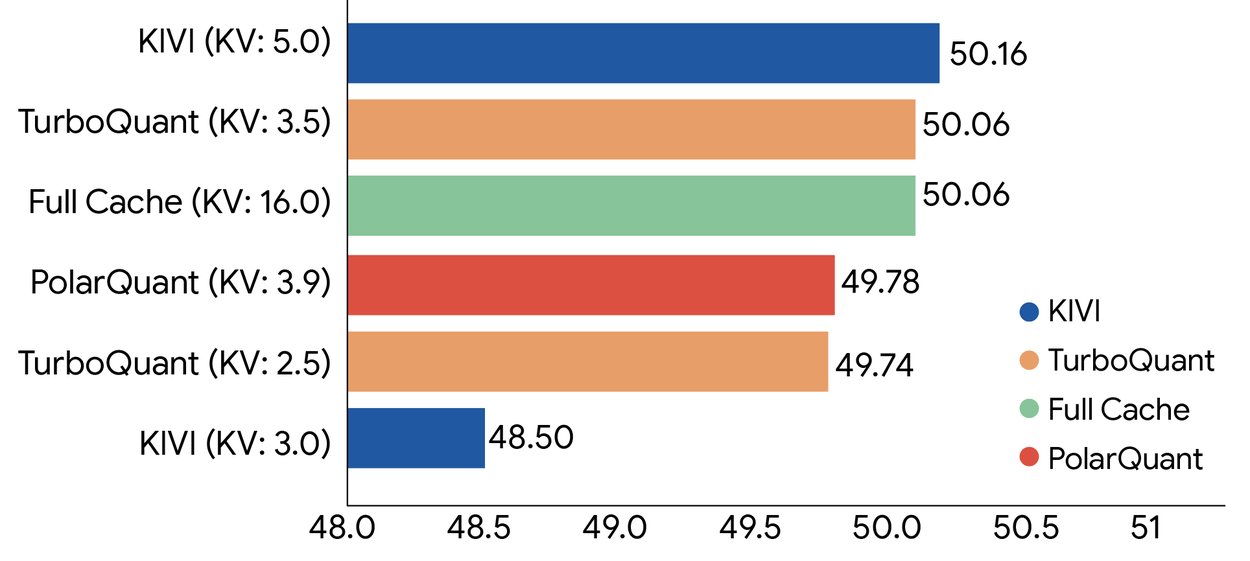
TurboQuant, key-value cache’i eğitim veya fine-tuning gerektirmeden sadece 3 bit’e sıkıştırabiliyor. Ve bunu model doğruluğundan ödün vermeden yapıyor. Üstelik orijinal LLM’lerden daha hızlı çalışma zamanı elde ediyor.
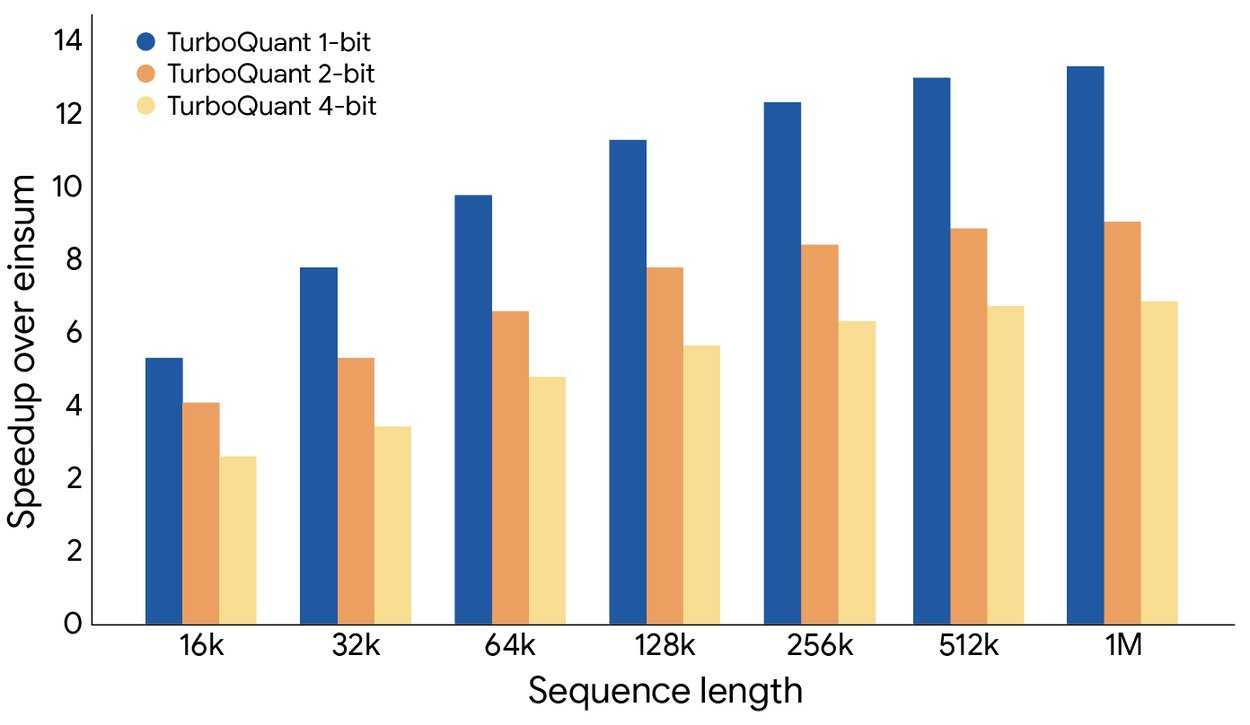
Hız tarafında rakamlar oldukça net: 4-bit TurboQuant, H100 GPU hızlandırıcılarda 32-bit quantize edilmemiş anahtarlara göre 8 kata kadar performans artışı sağlıyor. Bu sadece bellek tasarrufu değil, aynı zamanda ciddi bir hız kazanımı demek.
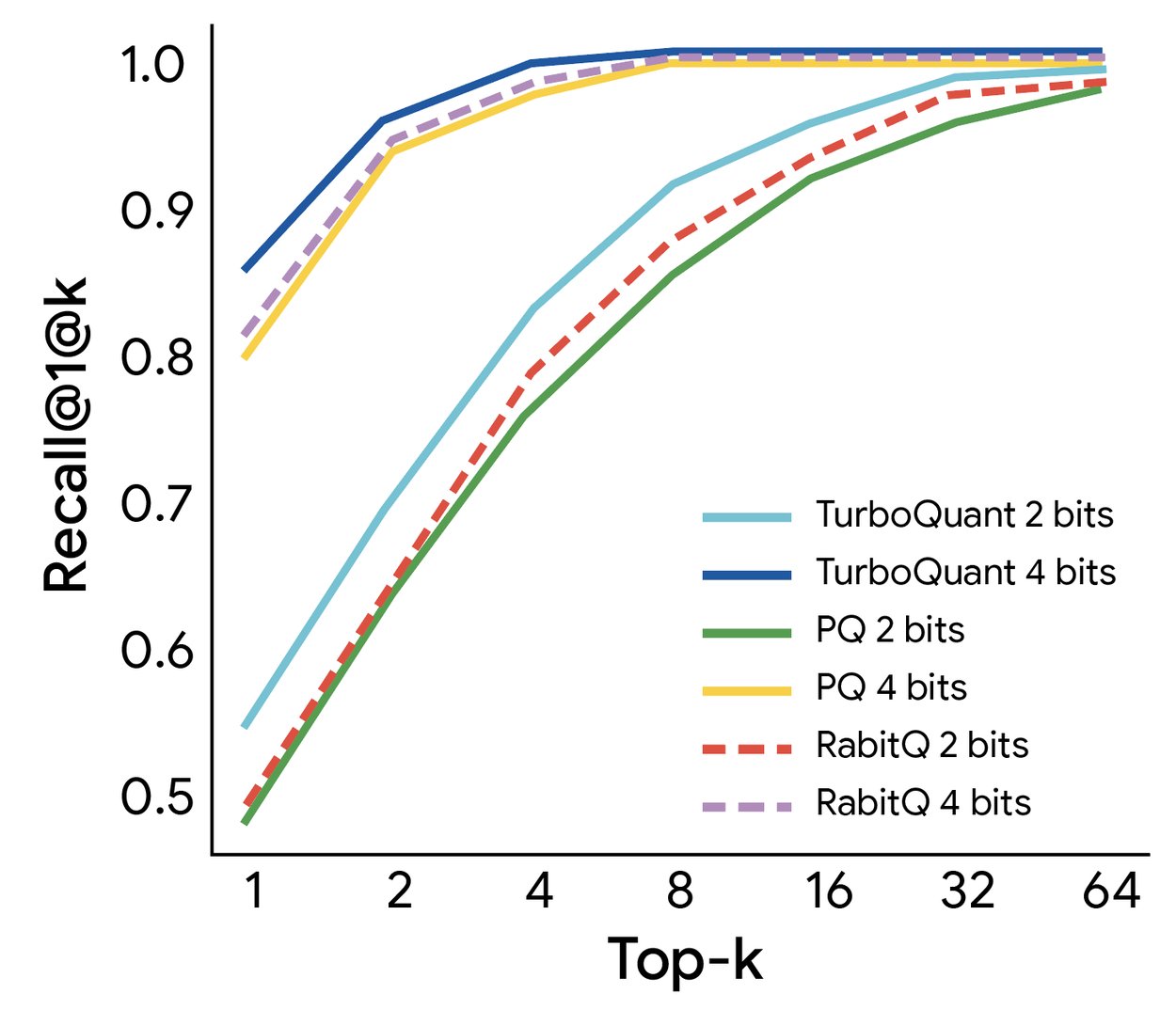
Vector search tarafında da durum benzer. PQ ve RabbiQ gibi mevcut yöntemlere karşı 1@k recall ratio ile değerlendirildiğinde, TurboQuant tutarlı şekilde daha yüksek recall oranları elde ediyor. Rakip yöntemler verimsiz büyük codebook’lar ve veri setine özel ayarlama kullanmasına rağmen bu sonuç geçerli.
Bundan sonrası
Google Research ekibi, bu üç yöntemin sadece pratik mühendislik çözümleri olmadığını, güçlü teorik kanıtlarla desteklenen algoritmik katkılar olduğunu vurguluyor. Yöntemler teorik alt sınırlara yakın çalışıyor, yani daha fazla iyileştirme için çok az alan var. Bu tür bir matematiksel sağlamlık, büyük ölçekli sistemler için güvenilirlik anlamına geliyor.
Asıl uygulama alanı Gemini gibi modellerdeki key-value cache darboğazını çözmek olsa da, etkileri daha geniş. Modern arama artık sadece anahtar kelimelerle değil, niyet ve anlam üzerinden çalışıyor. Bu da milyarlarca vektör içeren veritabanlarında en yakın, anlamsal olarak en benzer öğeleri bulabilen vector search gerektiriyor. TurboQuant gibi teknikler, minimum bellekle, sıfıra yakın ön işleme süresiyle ve yüksek doğrulukla büyük vektör indeksleri oluşturmayı ve sorgulamayı mümkün kılıyor.
TurboQuant, “daha az bitle daha iyi sonuç” vaadini gerçekten tutabilen nadir çalışmalardan biri gibi görünüyor. 3 bit’e sıkıştırma yapıp doğruluk kaybetmemek, üstüne bir de hız kazanmak, kağıt üzerinde biraz fazla iyi duruyor. Ama benchmark sonuçları ve teorik temeller bunu destekliyor. Özellikle LLM’lerin inference maliyetlerinin sürekli gündemde olduğu şu dönemde, bu tür sıkıştırma teknikleri ciddi pratik değer taşıyor. ICLR 2026’daki sunumu beklemeye değer.
Kaynak: https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/