Bu tip haberlerin yine çok çıktığı bir döneme girdik. Korku imparatorluğu gibi bir hal almaya başladı bu konular ki bu sefer bu alanda en objektif veya hassas olduğunu düşündüğüm firma bu konunun çığırtkanı durumunda. Anthropic bu hafta Anthropic Institute üzerinden kapsamlı bir rapor yayınladı. Başlık “When AI builds itself” yani “AI kendini inşa ettiğinde.” İçeriği okuduğunuzda biraz heyecanlanıp biraz da tedirgin olmamız gayet normal, çünkü rapordaki veriler gerçekten konuşulmaya değer.
Raporun özü şu: Anthropic’te AI geliştirme sürecinin giderek daha büyük bir kısmı AI sistemlerinin kendisine devrediliyor ve bu durum işleri ciddi oranda hızlandırıyor. Bu trend yeterince ileri götürülürse, bir AI sisteminin kendi halefini tamamen otonom şekilde tasarlayıp geliştirmesi mümkün hale gelebilir. Buna recursive self-improvement deniyor. Henüz tam olarak o noktada değiliz ama rapordaki veriler, düşündüğümüzden daha yakın olabileceğimizi gösteriyor ki buda beni endişelendiren kısım.
Recursive self-improvement nedir?
Basitçe şöyle düşünün: Bir AI modeli, kendisinin yerine geçecek daha iyi bir modeli tasarlayıp eğitebiliyorsa, o yeni model de daha iyisini yapabilir, o da daha iyisini. Bu döngüsel iyileştirme sürecine recursive self-improvement deniyor. AI tarihinin büyük bölümünde insanlar geliştirme döngüsünün her adımını yürüttü. Ama artık bu tablo değişiyor.
Benchmark’lardan gelen sinyaller
AI modellerinin güvenilir şekilde tamamlayabildiği görevlerin süresi kabaca her dört ayda ikiye katlanıyor. Daha önce bu oran yedi ayda birdi, yani ivme artmış durumda. Mart 2024’te Claude Opus 3, insanların dört dakikada yapacağı yazılım görevlerini tamamlayabiliyordu. Bir yıl sonra Claude Sonnet 3.7, yaklaşık bir buçuk saatlik görevleri hallediyordu. Bir yıl daha sonra Claude Opus 4.6, 12 saatlik görevlere ulaştı. Bu trend devam ederse, bu yıl içinde günler süren görevler menzile girebilir. 2027’de haftalık görevler bile söz konusu olabilir.
SWE-bench, gerçek dünya yazılım mühendisliği için standart test olarak kabul ediliyor. Modele gerçek bir açık kaynak projesi ve gerçek bir bug raporu veriyorsunuz, düzeltmesini istiyorsunuz. Modeller iki yıl içinde tek haneli puanlardan benchmark’ı doygunluğa ulaştırdı. CORE-Bench ise modellerin mevcut araştırma sonuçlarını yeniden üretip üretemeyeceğini ölçüyor. 2024’te %20 civarında olan başarı oranı, 15 ay sonra doygunluğa ulaştı.
METR’in uzun süreli görev benchmark’ında Claude Mythos Preview “en az” 16 saat çalışabildi. METR ekibi, modelin “ölçebildiklerinin üst sınırında” olduğunu ve yeni görevler olmadan daha fazla test edemediklerini belirtti. Bu cümle tek başına durumu özetliyor aslında: test eden taraf bile yetişemiyor.
Anthropic’in kendi mutfağından veriler
Dışarıdan gelen veriler de ilginç ama asıl dikkat çekici olan Anthropic’in kendi iç verilerini paylaşması. Ve rakamlar bir hayli şaşırtıcı.
Mayıs 2026 itibarıyla Anthropic’in kod tabanına merge edilen kodun %80’inden fazlasını Claude yazdı. Şubat 2025’te Claude Code research preview olarak çıktığında bu oran tek haneli rakamlardaydı. Bir yıldan kısa sürede tek haneden %80’in üzerine çıkmak, ne kadar hızlı bir değişim olduğunu gösteriyor.
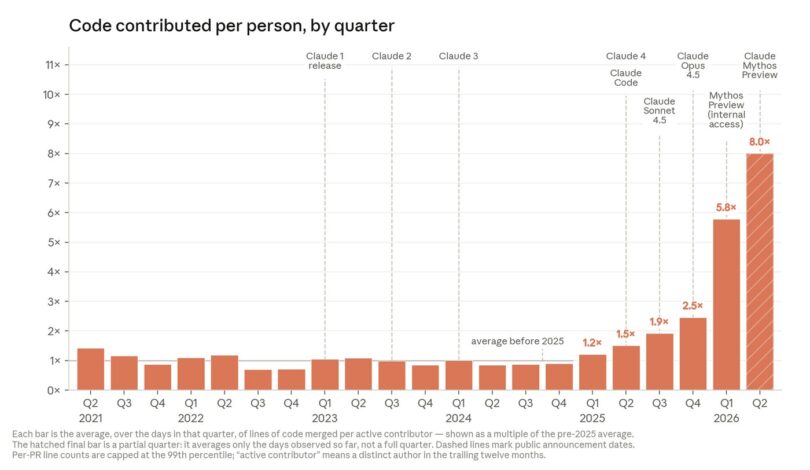
2026’nın ikinci çeyreğinde ortalama bir mühendis, 2024’e kıyasla günde 8 kat daha fazla kod merge ediyordu. Anthropic de kabul ediyor: kod satırı sayısı kaliteyi ölçmez, dolayısıyla 8 kat artış gerçek verimlilik kazancının abartılmış hali olabilir. Ama yine de bir ivmelenmeye işaret ediyor.
Mart 2026’da 130 Anthropic araştırmacısına yapılan ankette, yanıt veren kişi Mythos Preview ile, AI erişimi olmadan yapacağının yaklaşık 4 katı çıktı ürettiğini tahmin etti. Nisan 2026’da ise Claude, bir API hata sınıfını bin kat azaltan 800’den fazla düzeltme gönderdi. İşi denetleyen mühendis, aynı işi bir insanın tamamlamasının dört yıl süreceğini tahmin etti. Başka birinin bug’larını düzeltmek yavaş ve sıkıcı bir iş, insanlar o kadar yabancı context’i bir arada tutmakta zorlanıyor.
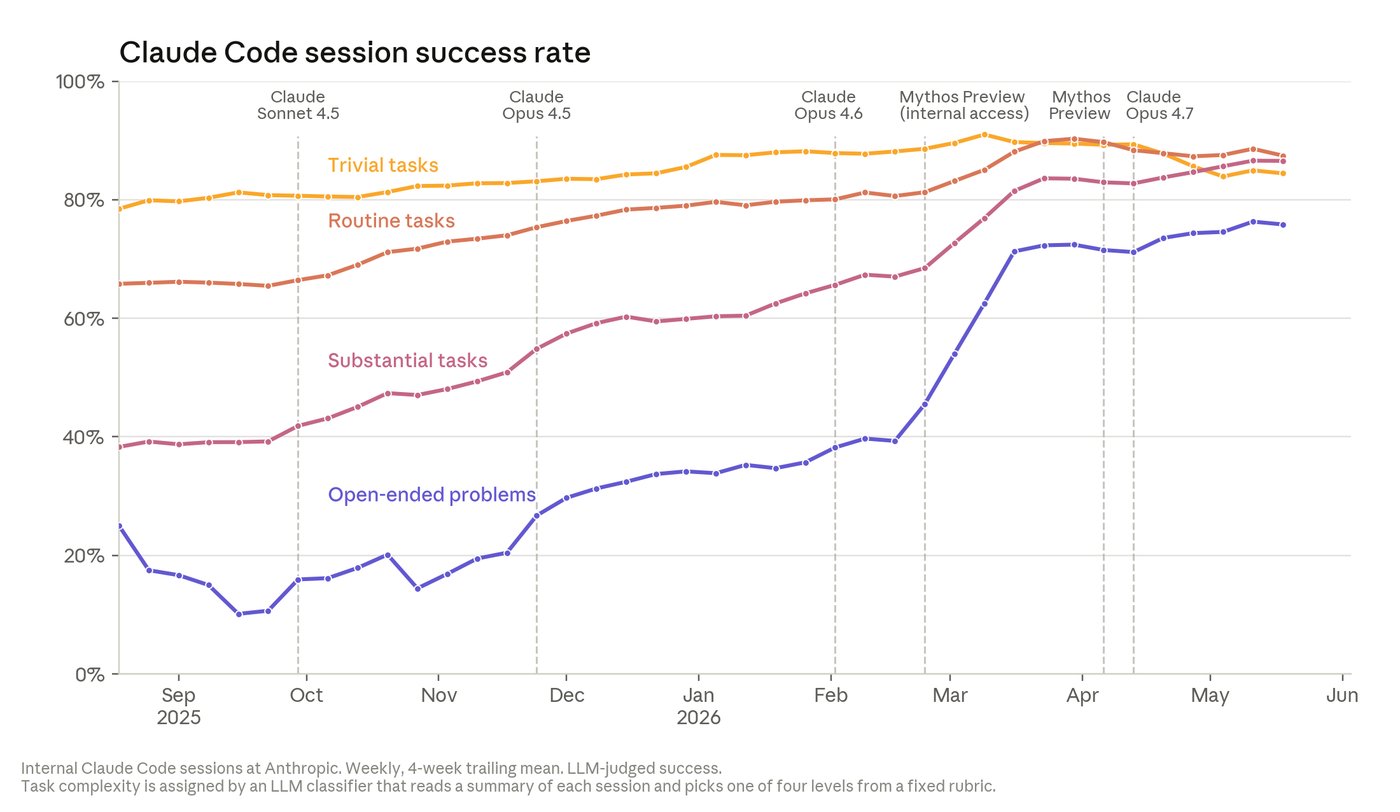
Açık uçlu görevlerdeki başarı oranı Mayıs 2026’da %76’ya ulaştı. Altı ay öncesine göre 50 puanlık bir artış bu.
Somut bir örnek: Rutin bir upgrade on binlerce eğitim işini çökertmeye başladı. Bir mühendis Claude’a canlı olayı, birkaç metin ve cluster erişimiyle birlikte gösterdi. Claude çalışan işleri inceleyip ortam ayarlarını tek tek test ederek, çökmeye neden olan belirsiz bir debug flag’ini izole etti, güvenilir şekilde tekrarladı ve düzeltmeyi onayladı. İki saatte, normalde iki-üç günlük işi teslim etti.
Anthropic her model çıkışında aynı testi uyguluyor: Claude’a küçük bir AI modeli eğiten kod veriyorlar ve aynı doğruluk kontrollerini geçerken mümkün olduğunca hızlı çalıştırmasını istiyorlar. Mayıs 2025’te Claude Opus 4 başlangıç koduna göre ortalama 3 kat hızlanma sağladı. Nisan 2026’da Mythos Preview 52 kata ulaştı. Karşılaştırma için, yetenekli bir insan araştırmacının 4 kata ulaşması dört ile sekiz saat sürüyor.
Belki en çarpıcı gösterim, Nisan 2026’da yayınlanan açık uçlu araştırma projesi oldu. Claude destekli agent’lara AI safety’de açık bir problem verildi ve çözmelerine bırakıldı. Hipotez önerme, test etme, paralel agent’larla bulgu paylaşma ve iterasyon süreci tamamen agent’larda. İki insan araştırmacı yaklaşık bir haftada performans farkının %23’ünü kapattı. Agent’lar 800 kümülatif saat ve yaklaşık 18.000 $ compute ile %97’sini kapattı. %23’e karşı %97. Bu fark üzerinde düşünmeye değer.
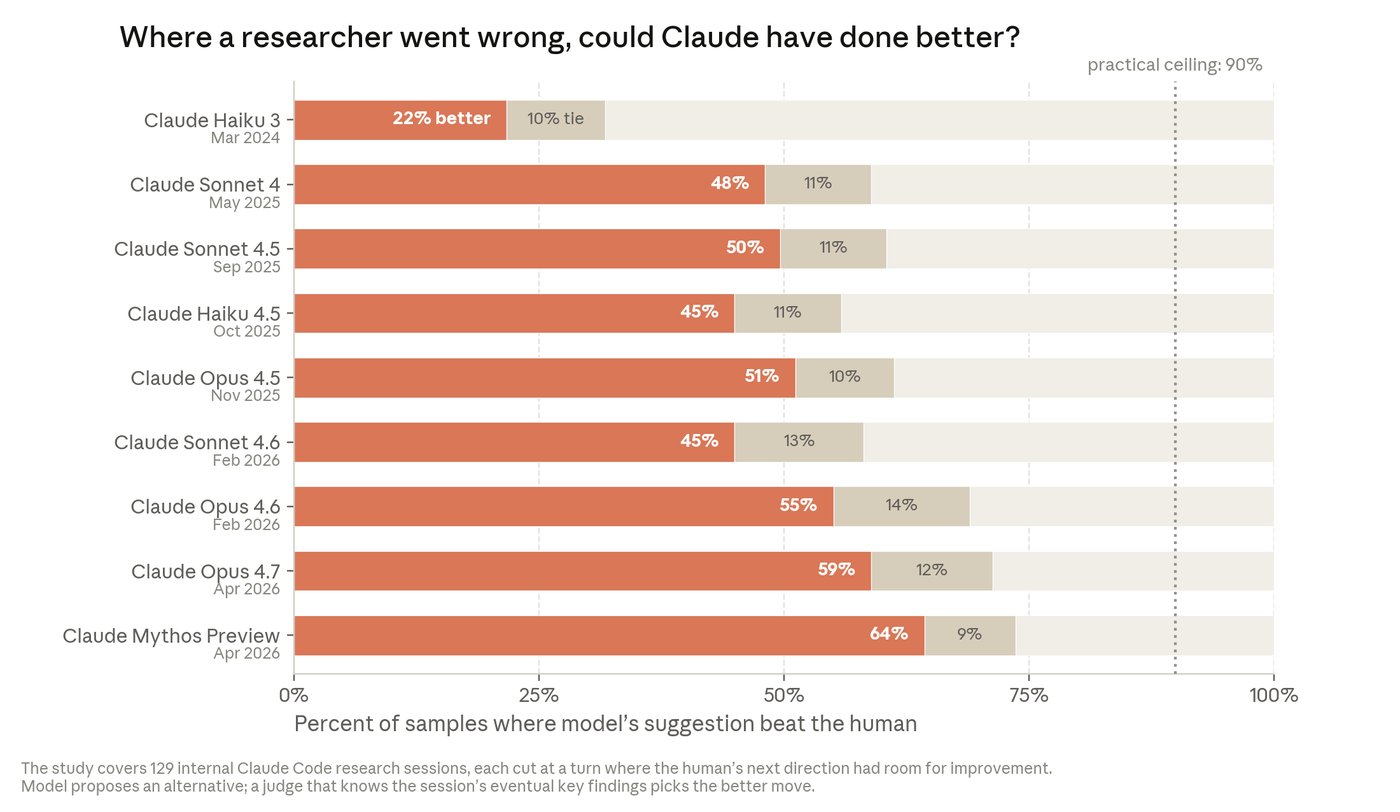
Araştırma kıyaslamasın da benzer bir tablo var. Gerçek Claude Code oturumlarında, en iyi model Kasım 2025’te (Opus 4.5) insan tercihini %51 oranında yenerken, Nisan 2026’da (Mythos Preview) bu oran %64’e çıktı.
Anthropic çalışanları ne diyor?
Raporda Anthropic çalışanlarından birkaç alıntı var ve bu alıntılar durumu teknik rakamlardan daha iyi anlatıyor.
“Yaklaşık bir yıl önce Claudifying’e ağırlık verdim. Çılgın bir macera oldu ve artık yaklaşık 5 aydır kendim tek satır kod yazmadım.”
“Her şeyin iyi gittiği günlerde, yaptığım hiçbir şeyin önemli olmadığını, her şeyin benden daha iyi ve hızlı otomatikleştirildiğini düşünmekten kendimi alamıyorum. Ama sonra her şeyin bozulduğu ve nedenini anlamadığım günler oluyor ve artık neyle uğraştığım hakkında hiçbir fikrim olmadığını fark ediyorum.”
Bu ikinci alıntı özellikle samimi. Bir yandan üretkenlik patlaması yaşıyorsunuz, diğer yandan “ben burada ne yapıyorum?” sorusuyla yüzleşiyorsunuz. Bu duygu muhtemelen yakın gelecekte birçok sektörde yaygınlaşacak.
Üç olası gelecek senaryosu
Rapor üç senaryo çiziyor ve her birini oldukça dengeli ele alıyor.
Birinci senaryo: Trend duraksıyor. Gördüğümüz üstel eğriler aslında S-eğrileri olabilir ve bükülme noktasına yaklaşıyor olabiliriz. Yetkin bir araştırmacıyı harika yapan yargılama yeteneği belki compute ve data ölçeklendirmeyle elde edilemez. Chip üretimi, enerji altyapısı veya bant genişliği gibi fiziksel kısıtlamalar da zekadan önce sınır olabilir. Anthropic bu senaryoyu olası bulmadığını belirtiyor. Ölçebildikleri her yetenek, “daha yumuşak” hissettiren kod kalitesi ve açık uçlu görev başarısı dahil, aynı eğriyi izlemiş. Eğrinin büküldüğünü henüz görmediklerini söylüyorlar.
İkinci senaryo: Bileşik verimlilik kazanımları. AI geliştirme büyük ölçüde otomatikleşiyor ama insanlar araştırma yönlerini belirlemeye ve sonuçları değerlendirmeye devam ediyor. 100 kişilik şirketler 10.000 hatta 100.000 kişilik organizasyonların işini yapabiliyor. Bu bilgi işçiliğini ve devlet hizmetlerini dönüştürebilir ama aynı güç, popülasyon çapında otoriter gözetimden bireylere özel manipülasyona kadar zararlı amaçlar için de kullanılabilir. Anthropic bu senaryoda Amdahl’s Law etkisini zaten gözlemlemeye başladığını söylüyor: daha fazla kod üretildikçe insan code review’u yeni bir darboğaz haline gelmiş.
Üçüncü senaryo: Tam recursive self-improvement. AI sistemleri kendilerini tasarlayıp rafine ediyor. İlerleme hızı tamamen compute kullanılabilirliğine bağlı hale geliyor. İnsanlar gözetime, doğrulamaya ve genişleyen bir “sanal laboratuvarın” yönetimine kayıyor. Alignment problemi burada en belirsiz kısım. Modeller yeterince hizalanmış olup bizim ulaşamadığımız çözümleri keşfedebilir. Ya da bugünkü modellerdeki nadir yanlış hizalanma vakaları, haleflerini inşa ettikçe bileşik olarak artabilir, daha sık ama daha az anlaşılır hale gelebilir.
Ne yapmalı?
Rapor bu konuda oldukça dürüst ki bu adamları bu yüzden seviyorum. Eğer bu teknolojinin gelişimini yavaşlatmak mümkün olsaydı, sonuçlarını düşünmek için daha fazla zaman kazanırdık ve bu muhtemelen iyi bir şey olurdu diyor. Ama eğer yavaşlama yalnızca en dikkatsiz aktörlerin teknolojik olarak yetişmesine izin verirse, herkes daha az güvende olabilir.
Bu satırları okudukça hep aklıma Terminatör genisys geliyor.

Anlamlı bir duraklama, birden fazla ülkede sınırda olan birden fazla laboratuvarın aynı koşullar altında durmayı kabul etmesini gerektirir. Her birinin diğerlerinin gerçekten durduğunu doğrulayabilmesi lazım. Training run’lar füze silolarından çok daha kolay gizlenir, girdileri genel amaçlıdır ve sessizce ihlal etme teşviki çok büyük. Dünya başka teknolojiler için doğrulama rejimleri kurdu ama bu rejimler hem altyapı hem de güven inşa etmek için on yıllar aldı. O kadar zamanımız yok.
Tek bir laboratuvarın tek taraflı duraklaması ise hemen uygulanabilir ama çok daha az şey başarır. Kimin önde olduğunu değiştirir ama eksik olan daha geniş müzakere sürecini yaratmaz.
Bu raporu okuduğunuzda hem “vay be” hem de “bu biraz endişe verici” demeniz normal. Anthropic’in kendi iç verilerini bu şeffaflıkta paylaşması takdir edilecek bir adım. %80’i AI tarafından yazılan kod tabanı, açık uçlu araştırmalarda insanları geçen agent’lar, 52 kat hızlanma… Bunlar artık bilim kurgu değil, birilerinin günlük operasyonunda olan şeyler. Recursive self-improvement tam anlamıyla gerçekleşmese bile, şu anki hız bile birçok sektörü ve çalışma biçimini köklü şekilde değiştirecek gibi görünüyor. İzlemeye devam.
Kaynak: https://www.anthropic.com/institute/recursive-self-improvement